Introduction and prerequisites
In this article we will be discussing the very basic knowledge that is required when we deal with natural language. We will begin with basic terminology and statistical laws which helps us understand the way the words behave in a natural language corpus. A corpus is usually defined as a collection of documents, where each document is a natural language text in our case. We will then move on to some processing techniques like tokenization and normalization and discuss the technical difficulties one can arrive at. We will also briefly discuss the n-gram framework widely used in natural language. One should be very well familiar with the concepts discussed in this article if the problem to be solved deals with natural language. There are no prerequisites for this article other than a basic understanding of conditional probabilities. After reading this article one can proudly say that he/she is familiar with Natural Language Processing. Once you get familiar with these concepts, you can use natural language tools like NLTK which have well updated libraries for everything discussed here.
Behaviour of natural language
Function words and Content words
- Function words have little meaning but serve as important elements for the structure of sentences
- The winfy prunkilmonger from the glidgement mominkled and brangified all his levensers vederously.
- Don’t know any content words but function words help form the structure
- Function words are closed-class words
- prepositions, pronouns, auxiliary verbs, conjunctions, grammatical articles, particles etc.
- Function words are the most common in a corpus
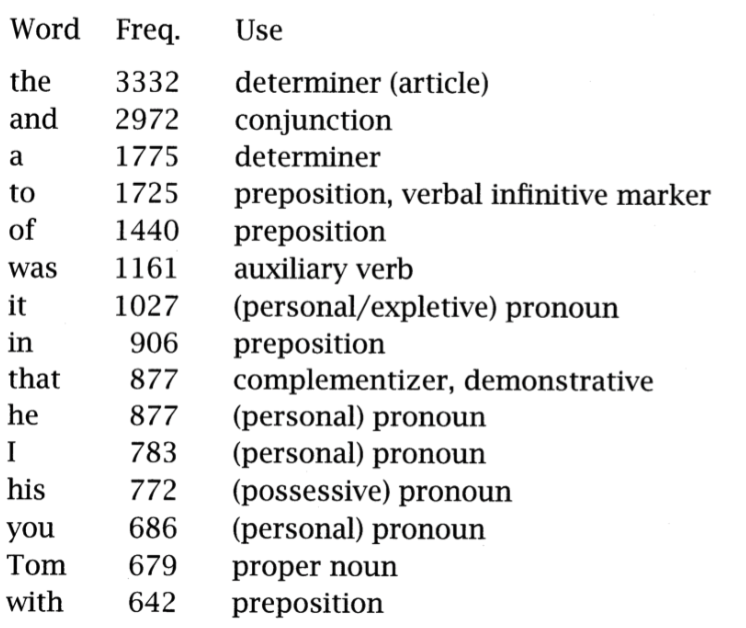
- The list is dominated by the little words of English, having important grammatical roles.
Types and Tokens
- A Type is a unique word whereas a Token can be any given instance of a given type.
- Type/Token Ratio - TTR
The type/token ratio (TTR) is the ratio of the number of different words (types) to the number of running words (tokens) in a given text or corpus.- This index indicates how often, on average, a new ‘word form’ appears in the text or corpus.
- Mark Twain’s Tom Sawyer
- 71k tokens, 8k types… TTR = 0.1
- Complete Shakespeare Work
- 884k tokens, 29k types… TTR = 0.03
- Empirical Observations
- TTR scores the lowest value (tendency to use the same words) in conversation.
- TTR scores the highest value (tendency to use different words) in news.
- Academic prose writing has the second lowest TTR.
- Higher TTR -> expert in grammar
- But TTR can not be representative of text complexity itself
- Varies with size of text…
- For a valid measure,… a running average is computed on consecutive 1000-word chunks of the text.
Word Distribution from Tom Sawyer
- TTR = 0.11 hence words occur avg. 9 times each?
- Yes, but words have a very uneven distribution:
- 3993 (50%) word types appear only once
- Called happax legomenon (pl. happax legomena)
- “Read only once” in greek
- Common words are common too
- 100 words account for 51% of all tokens of all text.

Zipf's Law
- A relationship between the frequency of a word (f) and its position in the list (its rank r).
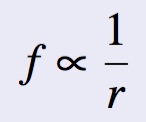
- Can also be stated as
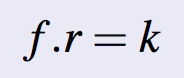
- Can also be stated as
- e.g. the 50th most common word should occur with 3 times the frequency of the 150th most common word.
- In terms of probability:

- The value of A is found closer to 0.1 for an english corpus
- More generally: it is ra however a is usually very close to 1.
- This is an empirical law and no concrete statistical explanation is yet known.
Zipf's other laws
- Correlation: Number of meanings and word frequency
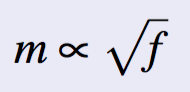
- Using the first law, we have
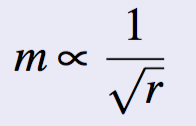
- Using the first law, we have
- Correlation: Word Length and Word Frequency
Word frequency is inversely proportional to their length.
- Stopwords account for a large fraction of text, hence we can eliminate them… greatly reduces the number of tokens in a text
- Most words are extremely rare and thus, gathering sufficient data for meaningful statistical analysis is difficult for most words.
Heap's Law
- Size of overall vocabulary (no. of types) vs the size of the corpus (no. tokens). Let |V| be the size of vocabulary and N be the number of tokens, then:
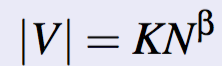
- K = 10-100
- β = 0.4-0.6, hence typically square root proportional.
Text Processing
Sentence Segmentation
- Depending on the application this may be needed
- The problem of deciding where the sentences begin and end.
- Challenges in English:
- While ‘!’, ‘?’ are quite unambiguous
- Period “.” is quite ambiguous and can be used additionally for abbreviations and numbers.
- Possible Approach
- Build a Binary Classifier
- For each “.”
- Decides EndOfSentence/NotEndOfSentence
- Classifiers can be
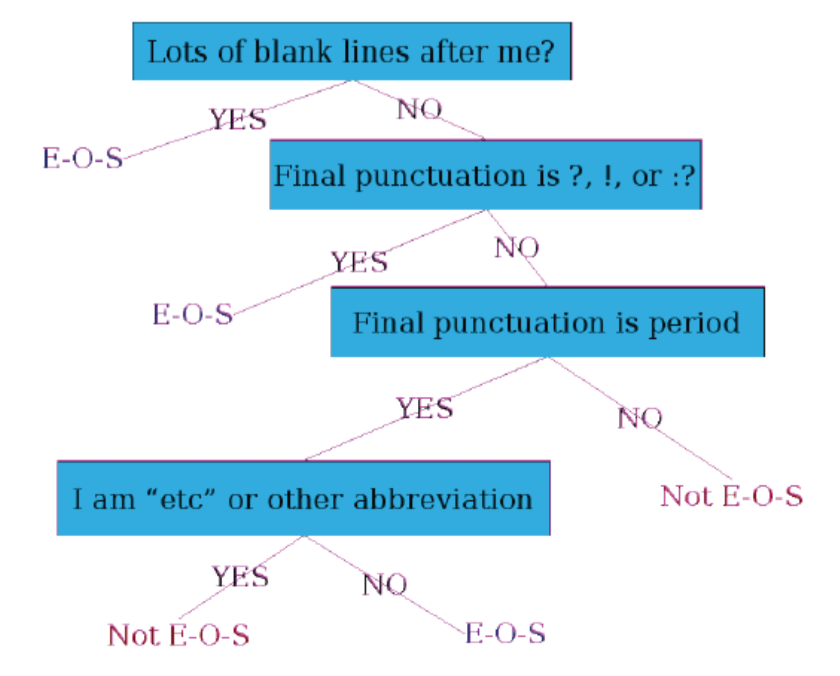
- Rule Based: e.g. Decision Tree Example for the word being End-Of-Sentence (E-O-S)
- Grammar Based,
- or Machine Learning Classifiers.
- Support Vector Machines
- Logistic Regression
- Neural Networks!
- Rule Based: e.g. Decision Tree Example for the word being End-Of-Sentence (E-O-S)
- Features could be
- Spaces after period
- case of word after “.” : lower, upper, cap, number
- case of word with “.” : lower, upper, cap, number
- Numeric features
- Length of the word with “.”
- Probability that (word with “.” occurs at end-of-sentence)
- Probability (word after “.” occurs at beginning-of-sentence)
- Implementing Decision Trees:
- Just an if-then-else statement…
- Choosing the features is more important
- For numeric features, thresholds are to be picked.
- With increasing features including numerical ones, difficult to set up the structure by hand
- Decision Tree structure can be learned using machine learning over a training corpus.
- Usually works top-down, by choosing a variable at each step that best splits the set of items.
- Popular algorithms: ID3, C4.5, CART
Tokenization
- What is tokenization?
- Tokenization is the process of segmenting a string of characters into words
- E.g. “I have a can opener; but I can’t open these cans.”
- Token: An occurence of a word
- Total 11 Word Tokens
- Type: A different realization of a word
- Total 10 Word Types
- Token: An occurence of a word
- Many Good Tokenizers Exist:
- NLTK Toolkit (Python)
- Stanford CoreNLP (Java)
- Can even be done by Unix Commands
- tr -sc ’A-Za-z’ ’\n’ < ../../working/wiki.txt | sort | uniq -c
- What this does:
- Change all non-alphabetic characters to newline
- Sort in alphabetic order
- Merge and Count Each Type
- Issues in Tokenization
- Do we need to Split the word?
- Finland’s → Finland Finlands Finland’s ?
- Do we need to expand the the word?
- What’re, I’m, shouldn’t → What are, I am, should not ?
- Existing Entities
- San Francisco → one token or two?
- Abbreviations
- m.p.h. → ??
- For information retrieval, generally use the same convention for documents and queries
- Handling Hyphenation, hyphens could be
- End-of-Line Hyphen
- Words divided at the end of line or splitting whole words into part for text justification
- This paper describes MIMIC, an adaptive mixed initia-tive spoken dialogue system that provides movie show-time information.
- Lexical Hyphen
- Certain prefixes are offen written hyphenated, e.g. co-, pre-, meta-, multi-, etc.
- Sententially Determined Hyphenation
- Mainly to prevent incorrect parsing of the phrase. Explicit mention. Some possible usages:
- Noun modified by an ‘ed’-verb: case-based, hand-delivered
- Entire expression as a modifier in a noun group:
- three-to-five-year direct marketing plan
- Mainly to prevent incorrect parsing of the phrase. Explicit mention. Some possible usages:
- End-of-Line Hyphen
- Language Specific Issues:
- French:
- l’ensemble: want to match with un ensemble
- German:
- Noun compounds are not segmented
- Lebensversicherungsgesellschaftsangestellter
- Compound splitter required for German information retrieval
- Chinese and Japanese: No Space Between Words
- Sanskrit
- Samas and Sandhi
- In such cases we need something called “Word Segmentation”
- French:
- Word Segmentation or Word Tokenization
- Greedy algorithm for Chinese
- Maximum Matching
- Start a pointer at the beginning of the string
- Find the largest word in dictionary that matches the string starting at pointer
- Move the pointer over the word in string.
- Word Tokenization also might be required for English Text
- #ThankYouSachin
- Greedy algorithm for Chinese
- Do we need to Split the word?
Normalization
- Indexed Text and Query Terms must have the same form.
- U.S.A. and USA should be matched
- We implicitly define equivalence classes of terms
- Some possible basic rules
- Reduce all letters to lower case
- However Upper Case in mid sentence might carry some information of being a proper noun or named entities
- Also, it protects US from us
- Reduce all letters to lower case
- Lemmatization
- Process of grouping together the different inflected forms of a word so they can be analysed as a single item
- am,are,is→be
- car, cars, car’s, cars’ → car
- Have to find the correct dictionary headword form
- Process of grouping together the different inflected forms of a word so they can be analysed as a single item
- Morphology
- Study of internal structure of words
- Words are built from smaller meaningful units called Morphemes
- Free morphemes works independently, whereas bound morphemes do not.
- Two categories:
- Stems:
- The core meaning bearing units
- Affixes
- The bits and pieces adhering to stems to change their meanings and grammatical functions
- Prefix: un-, anti-, etc.
- Suffix: -ity, -ation, etc.
- Infix: E.g. in sanskrit: ’n’ in ‘vindati’ , contrasted to ‘vid’
- Stems:
- Stemming
- Reducing terms to their stems, used in information retrieval
- vs Lemmatization
- Both related to grouping inflectional forms and sometimes derivationally related forms of a word to a common base form
- Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time.
- Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma.
- Also, lemmatisation can in principle select the appropriate lemma depending on the context. e.g. meeting -> verb meet or noun meeting
- Crude Chopping:

- Example: Porter’s Algorithm Rules for Stemming
- 1a.
- sses → ss (caresses → caress)
- ies → i (ponies → poni)
- ss → ss (caress → caress)
- s → φ (cats → cat)
1b.
- (*v*)ing → φ (walking → walk, king → king)
- (*v*)ed → φ (played → play)
- ational → ate (relational → relate)
- izer → ize (digitizer → digitize)
- ator → ate (operator → operate)
- al → φ (revival → reviv)
- able → φ (adjustable → adjust)
- ate → φ (activate → activ)
- 1a.
The n-grams technique
What are n-grams?
- An n-gram is a contiguous sequence of n items from a given sequence of text.
- When the items are words, n-grams may also be called shingles.
- An n-gram of size 1 is referred to as a unigram; size 2 is a bigram (or, less commonly, a "digram"); size 3 is a trigram.
- Larger sizes are sometimes referred to by the value of n, e.g., "four-gram", "five-gram", and so on.
Applications
- A type of probabilistic language model for predicting the next item a sequence (discussed in the next sub-section.)
- Used as features for in various classification/modeling tasks, e.g. Machine Translation.
- In speech recognition, phonemes and sequences of phonemes are modeled using a n-gram distribution
- For language identification, sequences of characters/graphemes (e.g., letters of the alphabet) are modeled for different languages.
- Although often criticized theoretically, in practice, n-gram models have been shown to be extremely effective in modeling language data, which is a core component in modern statistical language applications.
Probabilistic Language Modelling
- Goal:
- Compute probability of a sequence of words
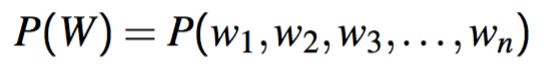
- Or, related task: probability of an upcoming word
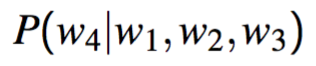
- Compute probability of a sequence of words
- Follow the chain rule:
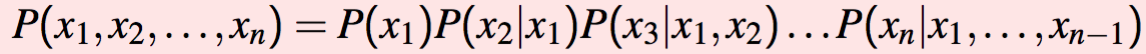
- Hence:
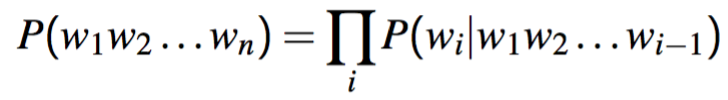
- Estimating these values:

- Problem is after a given length, your data sets cut short.
- Estimating these values:
- Markov Assumption
- k-th order model:
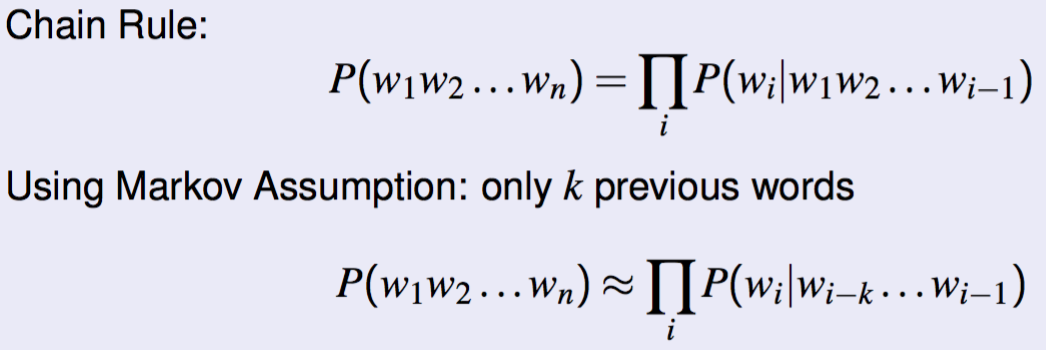
- k-th order model:
- N-gram modelling equivalent to (n-1) order markov model
- We usually extend to trigrams, 4-grams, 5-grams…
- But language has long-distance dependencies
The computer which I had just put into the machine room on the fifth floor crashed.- This is less frequent and we usually get away with n-gram models.
- But language has long-distance dependencies
- While estimating probabilities, we can also count on the start symbols for sentences… something like:

- Workout example: 9222 Restaurant Sentences
- Bigram Counts:
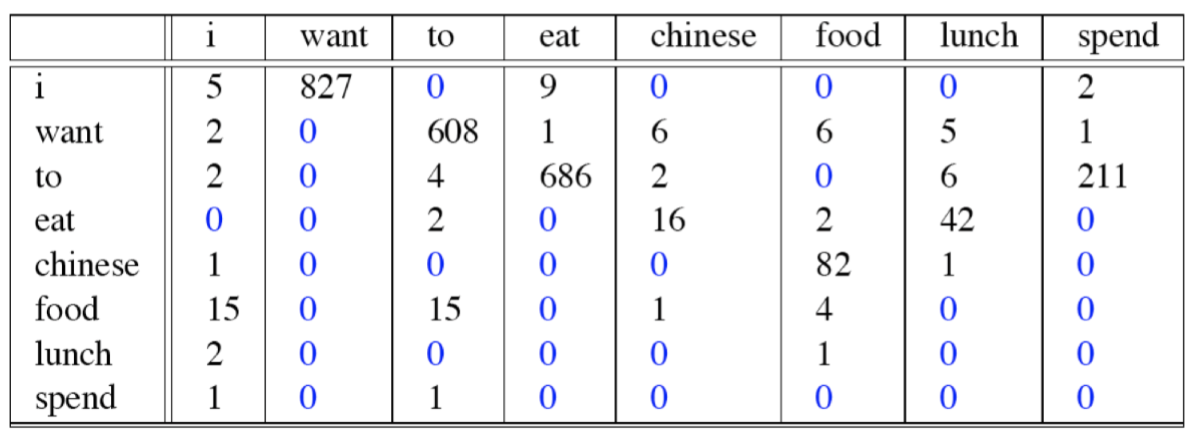
- Unigram Counts:

- Result:
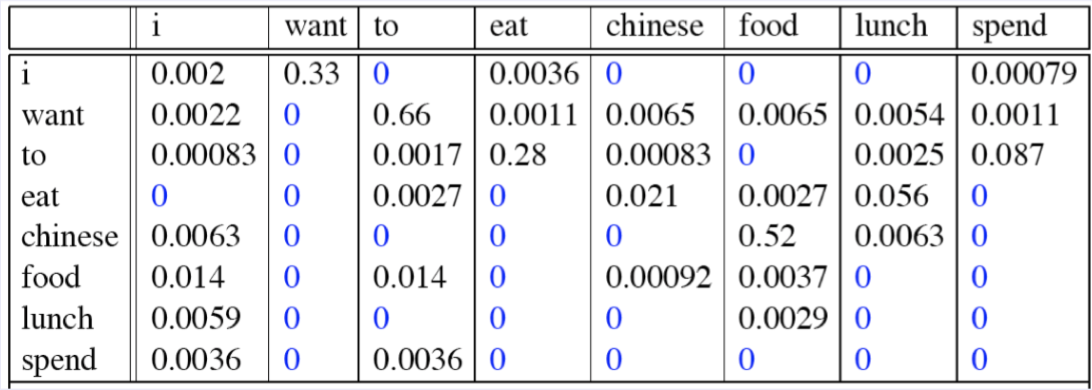
- Computing Sentence Probability:

- Bigram Counts:
- Workout example: 9222 Restaurant Sentences
- Practical Issues
- We do things in log space
- Avoids Underflow
- Adding is faster than multiplying
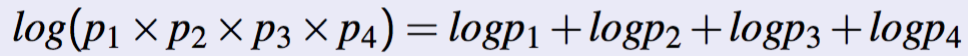
- Handling Zeros
- Use Smoothing … Taught Later
- We do things in log space
- Google released its N-Grams in 2006.
Generalization and the problem of Zeros
- The Shannon Visualization Method
- Use language model to generate word sequences
- Choose a random bigram (<s>,w) as per its probability (choose anything from 0 to 1)
- Choose a random bigram (w,x) as per its conditional probability (choose anything from 0 to 1)
- And so on until we choose </s>

- Shakespeare as Corpus
- 884k tokens, 29k types
- Shakespeare produced 300,000 bigram types out of V2 = 844 million possible bigrams.
- So 99.96% of the possible bigrams were never seen (have zero entries in the table)
- Quadrigrams worse: What's coming out looks like Shakespeare because it is Shakespeare.

- In the unigram sentences, there is no coherent relation between words, and in fact none of the sentences end in a period or other sentence-final punctuation.
- The bigram sentences can be seen to have very local word-to-word coherence (especially if we consider that punctuation counts as a word)
- The trigram and quadrigram sentences are beginning to look a lot like Shakespeare.
- Indeed a careful investigation of the quadrigram sentences shows that they look a little too much like Shakespeare.
- It cannot be but so are directly from King John
- The above is a peril of overfitting
- N-grams only work well for word prediction if the test corpus looks like the training corpus
- In real life, it often doesn’t
- We need to train robust models that generalize!
- In extreme case we can even arrive at the problem of zeros
- Problem of zeros:
- Zero probability n-grams
- P(offer | denied the) = 0
- The test set will be assigned a probability 0
- And the perplexity can’t be computed
- Solution: Smoothing Techniques
- Laplace Smoothing (Add-one Estimation)
- Pretend we saw each word (N-gram in our case) one more time than we did
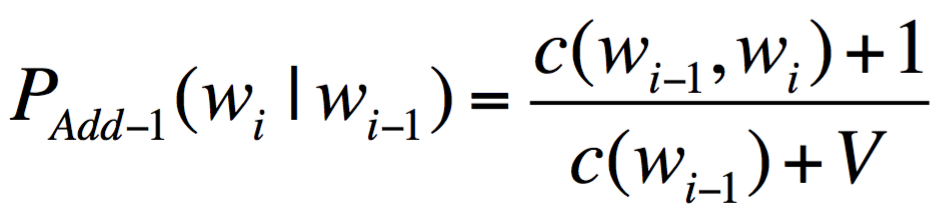
- Add-k Estimate
- Unigram Prior Smoothing
- Good-Turing Estimation
- Kneser-Ney Smoothing
- Laplace Smoothing (Add-one Estimation)

- Zero probability n-grams
Combination of Models
- As N increases
- Power of model increases
- But the ability to estimate accurate parameters from sparse data decreases (i.e. the smoothing problem gets worse).
- A general approach is to combine the results of multiple N-gram models.
References
- The Wikipedia Page for Lloyd's Algorithm
- SNLP 2015 course taught by Dr. Pawan Goyal at IIT Kharagpur. Ask for lecture slides by e-mail.
- Manning, Christopher D., and Hinrich Schütze. Foundations of statistical natural language processing. MIT press, 1999.
- NLP Lunch Tutorial: Smoothing., by Bill MacCartney
- Lecture slides for Language Modeling., by Dan Jurafsky